
Most enterprise buyers now expect security assurance artifacts before procurement. In the healthcare sector, unchecked ePHI exposures have become the norm: between 2009 and 2024 there were 6,759 breaches affecting more than 846 million individuals, and in 2024 the average number of exposed records was more than 758,000 per day. Regulators have responded with the Office for Civil Rights’ risk‑analysis initiative, which produced seven enforcement actions within its first six months and fines ranging from $25,000 to $3 million. Enterprise deals stall when healthcare organizations cannot demonstrate control design and evidence. I’ve overseen thousands of audits and have seen deals fall apart because classification wasn’t done or evidence was stale. This HIPAA Data Classification Guide draws on real delivery work—6,000+ audits and 25 years of combined expertise at Konfirmity—to explain why classification matters in 2026 and how to operationalize it.
HIPAA and the role of data classification
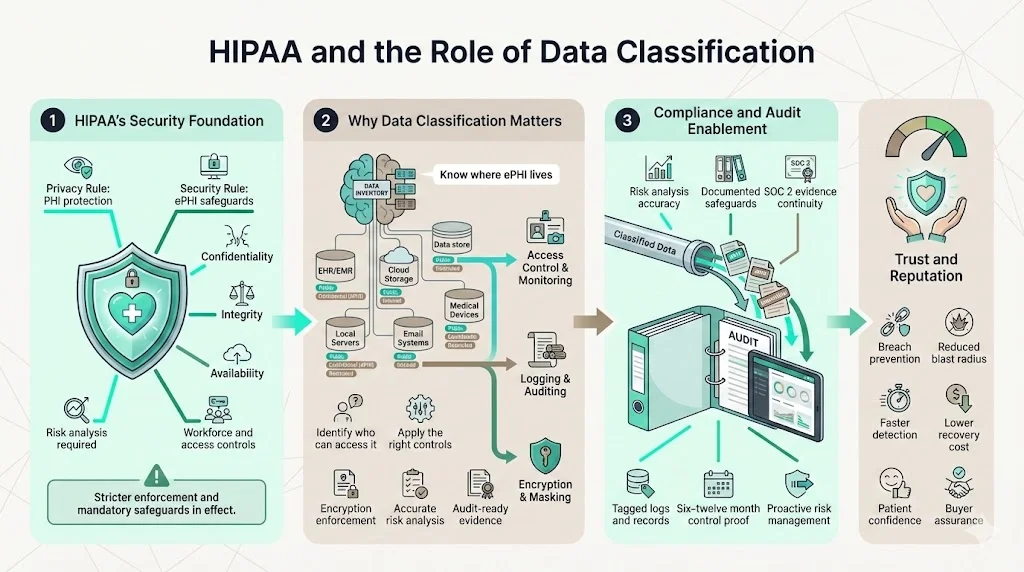
HIPAA is built on two core rules. The Privacy Rule protects all individually identifiable health information—PHI—held or transmitted by covered entities and their business associates. It prohibits disclosure except for permitted purposes and requires de‑identification when information is released publicly. The Security Rule compels organizations to ensure the confidentiality, integrity and availability of ePHI. It mandates risk analysis, workforce security, information access management, audit controls and contingency planning. Recent enforcement actions show regulators will no longer tolerate superficial compliance: OCR’s risk‑analysis initiative has already led to settlements for failing to conduct an adequate security risk assessment. Proposed rulemaking issued in January 2025 would eliminate the distinction between “required” and “addressable” standards and introduce mandatory encryption, asset inventory, network segmentation, multifactor authentication and continuous risk analysis.
Why classifying data matters for compliance
Classification underpins every safeguard in HIPAA. You can’t protect ePHI if you don’t know where it lives or who can access it. OCR’s enforcement actions reveal that regulated entities failed to conduct accurate risk analyses and didn’t document where ePHI resided. Proper classification allows organizations to apply the right controls, show auditors evidence of access and encryption, and manage risk proactively. For SOC 2 Type II, auditors must see evidence that controls operate over six to twelve months; classification ensures you collect and tag evidence consistently. From a business perspective, classification reduces the chance of catastrophic breaches—like the 2024 Change Healthcare ransomware attack, which exposed data of roughly 190 million people and cost UnitedHealth Group an estimated $2.87 billion—and protects the trust of patients and partners.
Patient trust and reputation
Healthcare is personal. When PHI is exposed, individuals suffer harm and lose confidence in their providers. The 2025 Cost of a Data Breach report found that healthcare breaches remain the most expensive, averaging $7.42 million per incident and taking 279 days to detect and contain. High‑profile incidents like the Change Healthcare breach forced providers to revert to paper billing and delayed patient care. These stories underscore why classification isn’t just about compliance—it protects people and preserves reputations. Patients and enterprise buyers will only trust organizations that can prove they have sorted, labelled and controlled their data.
Understanding healthcare data types
Protected health information (PHI)
PHI encompasses any individually identifiable health information that relates to an individual’s past, present or future physical or mental condition, the provision of health care to the individual or payment for care. Examples include medical records, lab results, billing information, insurance details, and associated identifiers such as names, addresses and dates of birth. Employment records maintained by a provider in its role as employer are not PHI, nor are education records covered by the Family Educational Rights and Privacy Act. Once data has been de-identified—through statistical analysis or removal of specified identifiers—it is no longer subject to HIPAA restrictions.
Personally identifiable information (PII) in health contexts
PII includes identifiers like names, phone numbers and account numbers. When this data is linked to medical diagnoses, treatments or payment details, it becomes PHI and must be protected accordingly. The classification boundary matters: a user’s email address alone may fall into a low‑risk tier; the same email paired with lab results elevates the data to PHI. Many breaches start with attackers targeting “low‑risk” data and then pivoting to sensitive systems. Proper classification and segregation prevent such lateral movement.
Other internal or operational data
Healthcare organizations generate a vast amount of data that isn’t PHI but still requires control—policies, procedure manuals, internal financials, supplier contracts, and quality assurance data. While disclosure of these documents may not trigger HIPAA penalties, unauthorized access could impact operations, reveal intellectual property or violate other regulations. Classifying these assets as moderate‑risk ensures they receive appropriate access controls and retention schedules.
Public health data and general information
Some information is meant for public dissemination—health education content, de‑identified research datasets and marketing materials. This data typically belongs in the low‑risk tier. However, caution is still needed: ensure de‑identification meets HIPAA standards and review content for inadvertent disclosure of PHI. In 2024, only 4% of organizations were able to mitigate cloud security incidents swiftly; misclassified “public” data that actually contained sensitive fields is a common root cause.
Core concepts of data classification
What data classification means
Data classification is the process of categorizing information according to its sensitivity, value and the impact if it is disclosed or altered. NIST recommends assigning impact levels—low, moderate and high—based on potential harm to confidentiality, integrity and availability. A low impact level corresponds to limited adverse effect, moderate to serious adverse effect, and high to severe or catastrophic effect. In the healthcare context, PHI is typically considered high impact because unauthorized disclosure can harm patients and lead to fines.
How classification supports sensitive data management
Once data is classified, organizations can define handling procedures. Low‑risk data may be stored openly and shared widely; moderate‑risk data should be restricted to internal personnel and protected with basic controls like authentication and audit logging; high‑risk data requires strong encryption, strict access management, continuous monitoring and formal incident response. Classification also informs retention schedules, backup strategies and destruction protocols. Without clear categories, teams misapply controls—either over‑protecting public information or under‑protecting PHI.
Classification vs. tagging vs. labeling
Classification assigns a sensitivity level based on risk. Tagging is the act of attaching metadata to data elements so that systems can enforce policies automatically. Labels are visual or technical markers—like “Confidential” or “PHI”—that signal how data should be handled. In practice, classification drives the tagging schema; tags facilitate automated detection and policy enforcement; labels communicate handling requirements to humans. Organisations often confuse classification with encryption. Encryption is a control that protects data at rest or in transit; classification is the policy that dictates which data must be encrypted and who may access it.
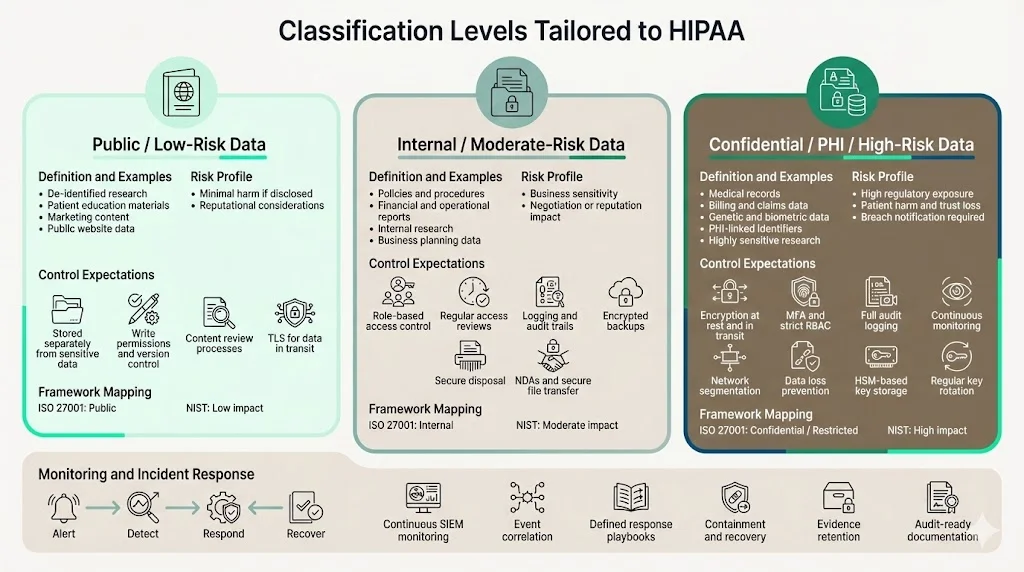
Classification levels tailored to HIPAA
To translate generic impact levels into a HIPAA context, this guide uses three tiers. These align with common frameworks such as ISO 27001’s public/internal/confidential/restricted model and NIST’s low/moderate/high impact categories.
Classify patient data to secure it, not just to satisfy a HIPAA tier.
Share your work email and protect PHI the way security-driven compliance demands.
Tier 1 – Public / low‑risk data
Definition and examples: Public data is information intended for broad distribution. Examples include de‑identified research summaries, patient education materials, marketing copy, and website content. The risk of harm if these data are disclosed is minimal, though reputational considerations still apply. In ISO 27001 terms, this aligns with the “public” classification; in NIST terms, it corresponds to a low impact level.
How to treat it safely: Store public data in systems separated from sensitive information. Enforce write‑permissions and version control to prevent unauthorized changes. Use content review processes to avoid accidental disclosure of PHI. Even though encryption isn’t required, consider TLS for data in transit to protect authenticity and integrity.
Tier 2 – Internal / moderate‑risk data
Definition and examples: Internal data includes operational documents, policies, procedures, financial reports and preliminary research. It may contain business‑sensitive information but does not meet the PHI definition. Unauthorized disclosure could affect negotiations, reveal pricing strategies or lead to embarrassment. ISO 27001 labels this tier “internal”, and NIST equates it to a moderate impact level.
Access control practices: Restrict access to personnel with a business need. Use role‑based access control (RBAC), and review privileges regularly. Implement logging and audit trails to detect inappropriate access. Encrypt backups and ensure secure disposal. Protect internal data when sharing with vendors by using non‑disclosure agreements and secure file transfer.
Tier 3 – Confidential / PHI / high‑risk data
Definition and examples: This tier covers all data that meets the PHI definition—medical records, billing information, genetic data, biometric identifiers and any PII linked to health care. It also includes other highly sensitive data such as payment card information, government‑issued IDs and proprietary research. In NIST terms, this is high impact; in ISO 27001 it matches “confidential” or “restricted”.
Encryption, role‑based access and security protocols: Encrypt all PHI at rest and in transit using strong algorithms. Use multifactor authentication and RBAC to limit access to those who have a legitimate purpose. Implement audit controls to log every access to PHI and review these logs regularly; the Security Rule requires audit controls. Segregate networks to prevent lateral movement and apply data loss prevention to detect exfiltration. Store encryption keys in a hardware security module and rotate them regularly.
Logging, monitoring and incident response: High‑risk systems require continuous monitoring and event correlation using security information and event management (SIEM) platforms. Define incident response procedures that include containment, eradication, recovery and post‑incident lessons. OCR settlements show that failing to track risk mitigation activities and audit progress leads to penalties. Document all actions taken and maintain evidence for your auditors.
Steps to implement a classification program
Inventory data sources
Start by cataloging where patient data lives: electronic health record (EHR) systems, email, secure messaging platforms, file shares, cloud services, backups and paper archives. Use automated discovery tools with pattern matching and machine‑learning algorithms to scan files for PHI markers such as names, dates and medical codes. This technology is essential because healthcare organizations hold vast amounts of unstructured data and manual inventory is prone to human error.
Classify and label data assets
After inventory, assign a tier to each dataset based on the sensitivity and potential impact. For structured data, classification rules can be automated—e.g., if a database table contains diagnosis codes or insurance numbers, label it Tier 3. For unstructured data, train staff to manually assess documents and apply labels. Use data classification tools that support tags and metadata so that downstream systems (access management, encryption, retention policies) can enforce rules automatically. As NIST’s high‑watermark principle dictates, if a dataset combines elements from multiple tiers, assign it the highest applicable level.
Apply data handling procedures
Based on classification, apply technical and administrative controls. For Tier 3 data, require encryption, multi‑factor authentication and least‑privilege access. For Tier 2, restrict sharing outside the organization and apply file‑integrity monitoring. For Tier 1, maintain version control and ensure proper approval processes. Document these procedures in policies accessible to all staff. Include requirements for transport encryption, cloud configuration (e.g., S3 bucket policies), and secure destruction of media.
Integrate into workflows and systems
Classification should not be an afterthought—embed it into every workflow. EHR exports should automatically tag PHI fields. Cloud applications must inherit data labels and apply them to backups and snapshots. Contracts with vendors and business associates should require recognition of your classification tiers and compliance with handling procedures. For SOC 2 and ISO 27001 audits, map classification tags to control evidence so that audits run smoothly.
Monitor, audit and update regularly
Classification is not a one‑time project. The OCR’s proposed rule would require annual risk analyses and continuous reviews. Set up automated scans to discover new data and ensure labels remain accurate. Audit access logs and review classification effectiveness during quarterly security reviews. Conduct formal reassessments when there are changes in technology, operations or threats. In our delivery experience, organizations that build classification into their continuous monitoring reduce misclassification incidents and avoid last‑minute scrambles during audits.
Best practices for healthcare teams
-
Standardize labels and criteria: Use consistent tier names and definitions across the organization and in contracts with vendors. Document the criteria that trigger each tier.
-
Educate your workforce: Train staff on what PHI is, why classification matters and how to apply labels. Use role‑specific training to help developers, clinicians and support staff recognize sensitive data.
-
Automate and use machine learning: Deploy tooling that uses optical character recognition and pattern matching to identify PHI in documents, spreadsheets and images. Automation reduces human error and scales to large datasets.
-
Enforce least‑privilege access: Map job roles to access levels and review rights regularly. Remove privileges immediately when a person’s role changes or they leave. The seventh enforcement action in OCR’s initiative involved former employees who still had access to a hospital’s systems.
-
Build audit trails: Maintain immutable logs of all access, modifications and data transfers. Use SIEM tools to correlate events and generate alerts.
-
Engage experts: Consult with security and compliance professionals who understand the intersection of HIPAA, SOC 2 and ISO 27001. Our team at Konfirmity acts as a dedicated CISO for our clients, embedding control design into their stack and managing evidence year‑round.
Challenges and how teams can overcome them
- Volume and variety of data: Healthcare organizations handle structured EHR records, unstructured free‑text notes, imaging data and vendor files. Automated discovery and classification tools help maintain visibility and reduce manual effort.
- Legacy systems and fragmented sources: Many hospitals still run legacy EHRs and on‑premises servers. Integrate discovery agents and implement network segmentation to isolate outdated systems. When migrating to cloud or hybrid environments, apply classification policies to new platforms.
- Misclassification and human error: Staff may mistakenly label PHI as public or vice versa. Provide clear guidelines and training; implement peer review of high‑risk classifications; and leverage automation for pattern recognition. Implementing the high‑watermark principle helps avoid under‑classification.
- Fragmented oversight: When multiple teams manage classification independently, policies drift. Centralize responsibility under a single security or privacy office. Use dashboards that show classification coverage, outstanding labels and audit findings.
Tools and technologies supporting data classification
Modern classification relies on integrated tooling:
-
Automated discovery and classification: Tools using pattern matching, machine learning and optical character recognition scan repositories for PHI markers, assign preliminary labels and flag potential misclassifications. This reduces manual workload and catches hidden data.
-
Integration with EHRs and cloud storage: EHR vendors now offer tagging functionality so that sensitive fields are labeled at the data model level. Cloud providers support object‑level tagging and policy enforcement—e.g., preventing public access to buckets containing Tier 3 data.
-
Data loss prevention (DLP) and SIEM: DLP solutions intercept sensitive data leaving email, web and endpoint channels, enforcing your classification policies. SIEM tools aggregate logs from endpoints, servers and cloud services, enabling real‑time detection of anomalies and audit trail retention.
-
Alerting and workflow: Look for tools that integrate classification with incident management. When a file is labeled Tier 3 and shared externally, the system should alert the security team and require approval.
Looking ahead: trends in healthcare data protection
Algorithm‑driven classification improvements: Advances in machine‑learning algorithms are improving the accuracy of automated classification. Techniques like natural language processing and image recognition can identify PHI in free‑text notes and scanned documents. These tools will help reduce misclassification and accelerate compliance.
Hybrid environments and multi‑cloud: According to IBM’s 2024 cost of a data breach report, 40% of breaches involve data across multiple environments. As healthcare organizations adopt cloud and hybrid architectures, classification policies must span on‑premises systems, SaaS applications and cloud infrastructure. Tools that map data flows and enforce policies consistently across environments are becoming essential.
Regulatory evolution: HHS has signaled stricter security expectations. Proposed modifications to the Security Rule would require mandatory encryption, network segmentation, asset inventories and annual risk analyses. OCR’s risk‑analysis initiative has already led to increased fines and oversight. Other frameworks are also evolving: ISO 27001:2022 introduced a new set of controls and emphasised information classification; SOC 2 now expects continuous evidence over longer observation periods. Healthcare organizations must monitor these changes and adjust classification programs accordingly.
Greater focus on vendor risk: The 2024 Change Healthcare ransomware event showed how third‑party providers can impact millions of patients. Business associate agreements should mandate classification and handling standards, and organizations should audit vendors for adherence. The risk‑analysis initiative’s settlements include cases where business associates failed to secure ePHI.
Conclusion
Data classification is the foundation of HIPAA compliance and effective security. It allows organizations to map their data, apply appropriate safeguards, provide continuous evidence and earn the trust of patients and buyers. Without it, risk analysis is incomplete, controls are misapplied and audits become reactive. As enforcement increases and breaches grow costlier, healthcare organizations must build classification into daily operations. Start with security and arrive at compliance: design controls that protect PHI, embed classification into your systems and workflows, and operate them continuously. A well‑run classification program reduces the likelihood of catastrophic breaches, shortens audit cycles and accelerates enterprise sales.
Frequently asked questions
1) What exactly counts as PHI under HIPAA?
PHI is any individually identifiable health information held or transmitted by a covered entity or its business associate in any form or medium. It includes demographic data related to the individual’s health, care or payment, along with identifiers such as names, addresses, birth dates and Social Security numbers. Employment records and certain educational records are excluded from the definition.
2) How is classification different from encryption?
Classification is a policy process: it assigns sensitivity levels to data and dictates how it should be handled. Encryption is a technical control that protects data against unauthorized access by converting it into cipher text. Classification informs whether data must be encrypted and who can access it. For instance, Tier 3 data (PHI) must be encrypted at rest and in transit, while Tier 1 data may not require encryption.
3) How often should classification be reviewed?
Classification should be revisited when there are changes in systems, operations or threats. The OCR’s proposed rule would require reviewing risk assessments—and thus classifications—at least annually and after significant changes. In practice, continuous monitoring and quarterly reviews are advisable. During audits, evidence of regular reviews demonstrates compliance.
4) Can automated tools fully replace manual classification?
Automated discovery and classification tools are invaluable for scanning large datasets and detecting PHI markers. However, they cannot fully replace human judgment. Context matters: a term like “Apple” could refer to a fruit or a technology vendor. Humans must verify automated labels, adjust rules and handle edge cases. Combining automation with expert oversight results in the most accurate classification programs.



