
Most enterprise procurement teams now require proof of security and compliance before they even start negotiating. Questionnaires ask about encryption, access controls, observation windows, and how data is handled. Without a reliable SOC 2 Data Classification Guide, deals stall, irrespective of how mature your product is. The American Institute of Certified Public Accountants (AICPA) built the Trust Services Criteria (TSC) to help auditors evaluate whether a service organisation’s controls are suitably designed and operating effectively. Yet hundreds of SaaS and cloud providers discover during the audit that their data handling practices – especially classification – are rudimentary. In 2025, the global average cost of a data breach remained above USD 4.4 million. Enterprise buyers know these numbers and expect evidence that partners can protect sensitive information. This guide shows how thoughtful data classification supports SOC 2 compliance, speeds up sales, and safeguards your business.
Why data classification matters more when selling to enterprise buyers
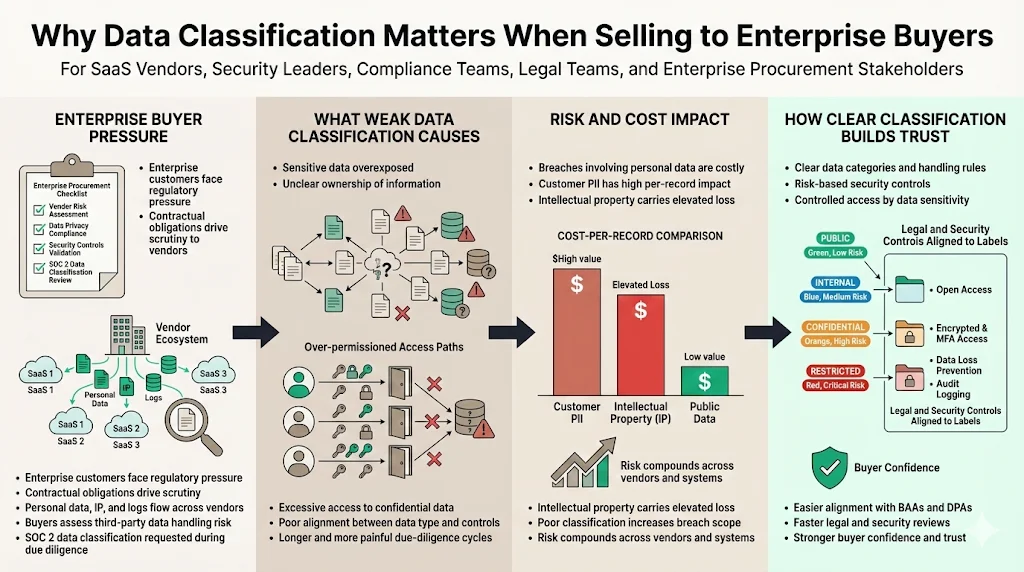
Enterprise customers operate under regulatory pressures and contractual obligations. They worry about personal data, intellectual property, and system logs travelling between dozens of vendors. When procurement teams request a SOC 2 Data Classification Guide, they are looking for tangible evidence that you understand and actively manage information risk. Weak classification leads to overexposed sensitive data, uncontrolled access, and longer due-diligence cycles. Conversely, clear classification demonstrates that your controls are risk‑based and helps legal teams align data protection clauses like Business Associate Agreements (BAAs) or Data Processing Agreements (DPAs). In a 2025 IBM report, the average cost per breached record for customer personally identifiable information (PII) was USD 160 and for intellectual property was USD 178. These statistics underline why enterprise buyers insist on classification as a foundation for trust.
How SOC 2 reviews expose weak data handling
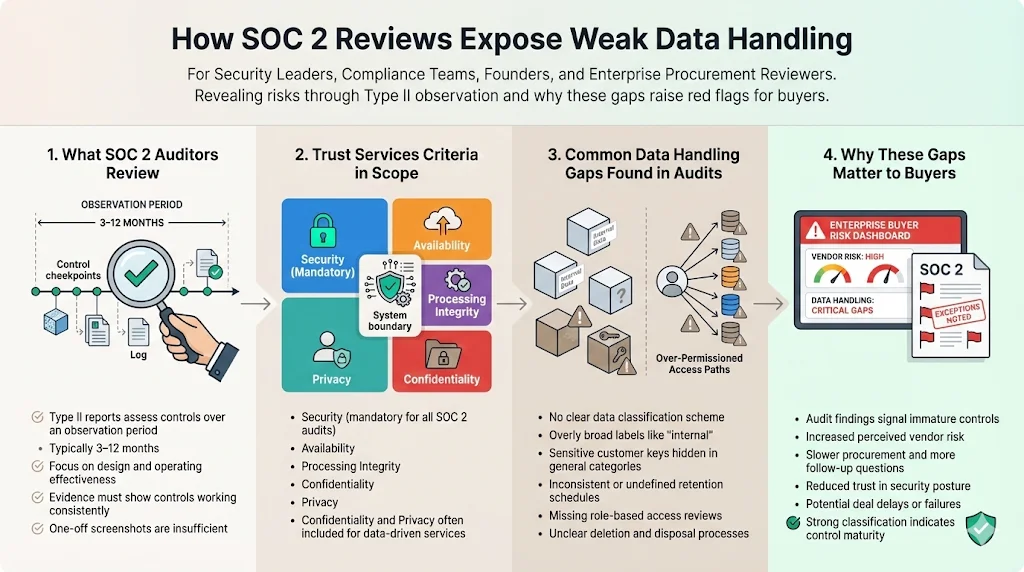
SOC 2 examinations focus on the design and operating effectiveness of controls over a specified observation period – usually between 3 and 12 months for Type II reports. Auditors map your controls against the five Trust Services Criteria: Security, Availability, Processing Integrity, Confidentiality, and Privacy. Security is mandatory for all engagements; confidentiality and privacy are optional but frequently in scope. When you cannot show how data is classified, stored, transmitted, and deleted, auditors see gaps. Examples include broad “internal” labels that hide sensitive customer keys, inconsistent retention schedules, or missing role‑based access reviews. These weaknesses not only lead to non‑conformities but also signal to buyers that your controls lack maturity.
What this SOC 2 Data Classification Guide will cover
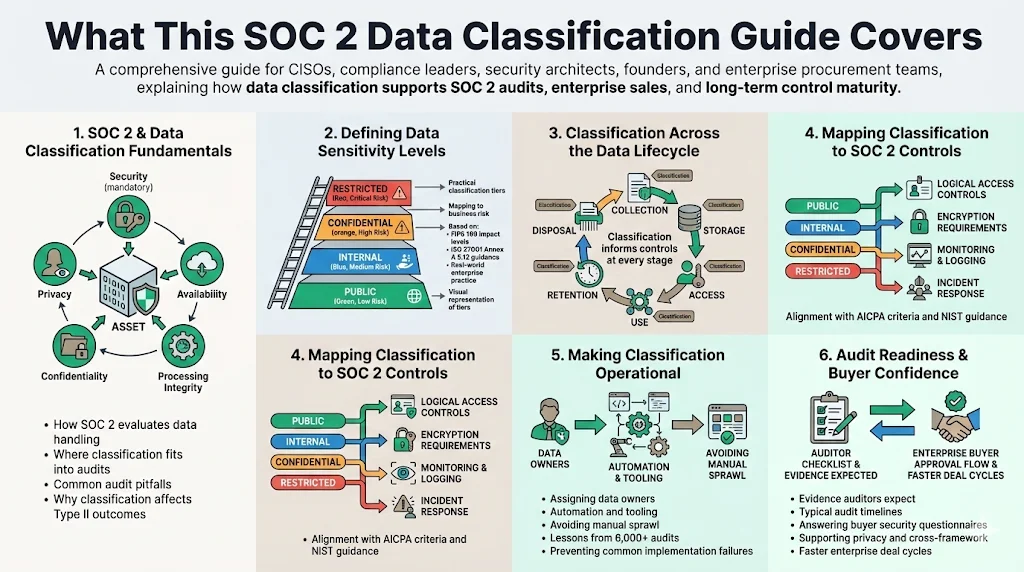
This comprehensive guide explains how to build a classification system that meets SOC 2 expectations and accelerates enterprise sales. It covers:
-
Understanding SOC 2 and data classification. We explain the Trust Services Criteria, how classification fits into audits, and common pitfalls.
-
Defining data sensitivity and confidentiality. Using FIPS 199 impact levels, ISO 27001 Annex A 5.12 guidance, and industry practice, we outline practical tiers and how they map to business risk. A visual infographic illustrates the tiers.
-
Mapping classification to the data lifecycle. From collection to disposal, classification should inform controls across storage, access, and retention.
-
Aligning classification with SOC 2 controls. We describe how classification underpins logical access, encryption, monitoring, and incident response, referencing AICPA criteria and NIST guidelines.
-
Operationalising classification. We share lessons from Konfirmity’s 6,000+ audits and 25+ years of combined expertise to show how to automate, assign ownership, and avoid common mistakes.
-
Preparing for audits and answering buyer questions. We offer concrete evidence strategies, typical timelines, and how classification supports privacy and cross‑framework compliance.
Understanding SOC 2 and Data Classification
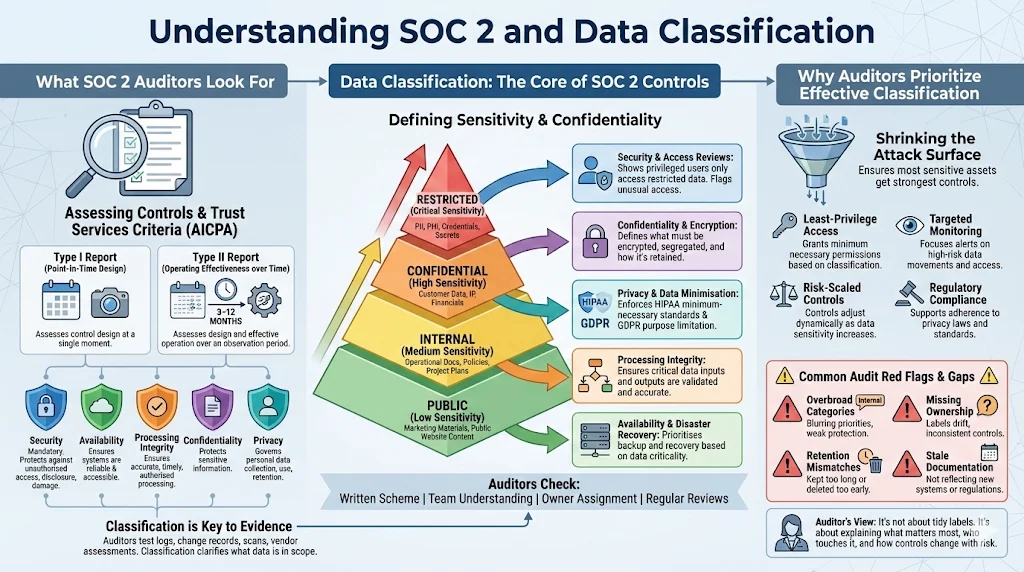
What SOC 2 looks for
SOC 2 audits evaluate whether a service organisation’s controls are suitably designed and operate effectively to meet one or more of the Trust Services Criteria. According to the Secureframe summary of the TSC:
Criterion
Purpose
Security (mandatory)
Protects systems and data from unauthorised access, disclosure, or damage.
Availability
Ensures systems remain reliable and available to meet business objectives.
Processing Integrity
Assures systems process data accurately, timely, and with authorised completion.
Confidentiality
Ensures confidential information is protected from unauthorised disclosure.
Privacy
Protects personal data in line with the organisation’s privacy commitments and regulations.
Under the AICPA’s guidance, a Type I report examines control design at a point in time; a Type II report also assesses operating effectiveness over an observation period, typically 3–12 months. Evidence may include access logs, change‑management records, vulnerability management results, vendor risk assessments, and ongoing monitoring. Classification touches each of these evidence areas because auditors need to know which data is in scope and how it is treated.
Where data classification fits into SOC 2 reviews
In a SOC 2 context, classification is the process of identifying and categorising data based on sensitivity and confidentiality. It informs which controls apply, how evidence is collected, and which trust criteria are in scope. For example:
-
Security: Access reviews must consider whether privileged accounts can read restricted data. Attack monitoring should flag suspicious access to sensitive logs.
-
Confidentiality: Controls should enforce encryption and segregation for confidential data; classification defines which data qualifies..
-
Privacy: When personal data or protected health information (PHI) is in scope, classification ensures you apply HIPAA’s minimum necessary standards and GDPR’s purpose limitation.
Auditors evaluate whether your classification scheme is documented, communicated, and consistently applied. They look at whether asset owners have assigned sensitivity levels according to legal requirements, business value, and potential impact. They also check that classifications are reviewed periodically to accommodate changes in data sensitivity.
Why auditors focus on how data is identified and handled
Effective classification reduces the attack surface by ensuring the most sensitive assets receive the strongest protection. It also aligns with AICPA criteria by supporting least‑privilege access, encryption, and monitoring. Without classification, service organisations often cannot demonstrate that controls scale with data criticality. Auditors routinely flag the following gaps:
-
Overbroad categories. Labelling everything “internal” dilutes focus and leads to unnecessary restrictions or exposures.
-
Missing ownership. When asset owners are not assigned, classification decisions are ad‑hoc and inconsistent.
-
Unaligned retention policies. Data is kept longer than necessary or deleted prematurely because retention rules are not tied to classification.
-
Outdated documentation. Classification schemes rarely account for new products, migration to cloud services, or evolving regulations.
What Data Classification Means in a SOC 2 Context
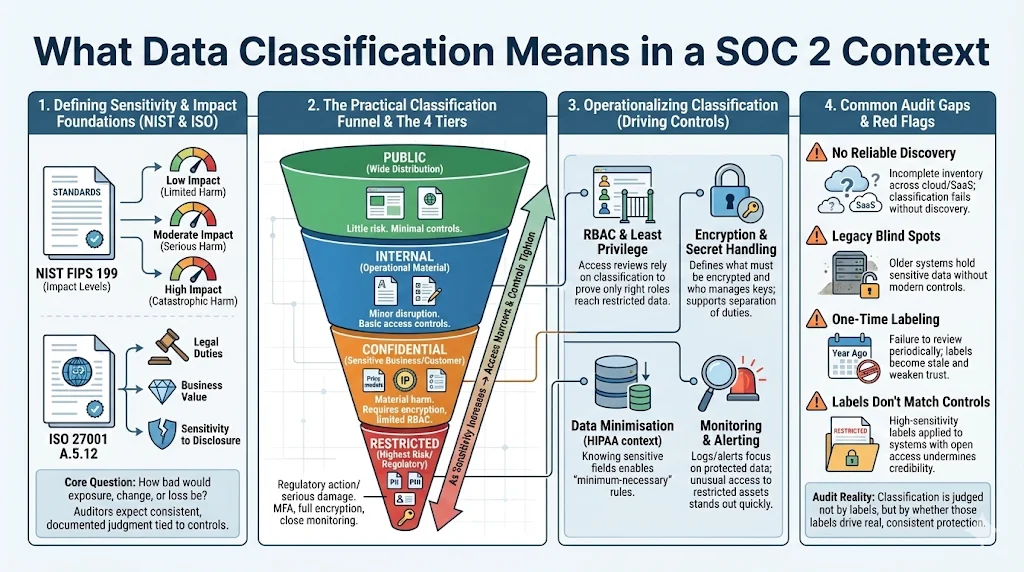
Defining data sensitivity and confidentiality levels
At its core, classification distinguishes between degrees of sensitivity. NIST’s FIPS 199 introduces impact levels – low, moderate, and high – for confidentiality, integrity, and availability. A low impact implies limited adverse effects; moderate implies serious adverse effects; high implies severe or catastrophic impact to the organisation or individuals. ISO 27001 Annex A 5.12 advises classifying information based on legal requirements, value, and sensitivity to unauthorised disclosure. Building on these standards and our experience, we recommend four tiers:
-
Public: Information intended for wide dissemination; minimal risk if disclosed (e.g., marketing materials).
-
Internal: Operational information requiring basic access controls (e.g., internal policies, project plans). Exposure may cause minor business disruption.
-
Confidential: Sensitive business or customer data (e.g., customer lists, financial forecasts, intellectual property) requiring encryption and restricted access.
-
Restricted: The most sensitive data, including PII, PHI, credentials, trade secrets, or keys. Requires multifactor authentication (MFA), encryption in transit and at rest, and continuous monitoring.
Below is an infographic that visualises these tiers. The funnel shape represents progressively tighter controls as sensitivity increases:
How classification supports data security and privacy controls
Proper classification is the foundation for technical and organisational measures. It enables:
-
Role‑based access control (RBAC). Only authorised users can access restricted data; access reviews verify that least‑privilege is enforced.
-
Encryption and cryptographic secret management. Sensitive data is encrypted using strong algorithms, and cryptographic secrets are managed with appropriate segregation of duties.
-
Data minimisation. HIPAA’s minimum necessary principle requires limiting PHI use and disclosure. Classification helps identify which fields fall under this principle.
-
Monitoring and alerting. Audit logs and security monitoring focus on protected data, raising alerts when unusual access patterns occur.
Common gaps auditors flag
Despite best intentions, many teams struggle with classification. Our audits frequently uncover:
-
Lack of discovery tooling. Teams do not know where all sensitive data resides, particularly across cloud platforms or third‑party SaaS. Without discovery, classification cannot be complete.
-
Legacy systems. Older systems store sensitive data without encryption or strong access controls. If classification stops at new systems, auditors view the programme as incomplete.
-
One‑time classification. Organisations classify assets once and forget. ISO 27001 requires regular reviews because data value and sensitivity change over time.
-
Mismatched labels and controls. Documents labelled “restricted” but stored in unencrypted repositories, or systems labelled “confidential” with public read access, undermine the credibility of classification.
Why Data Classification Is Critical for Enterprise Trust
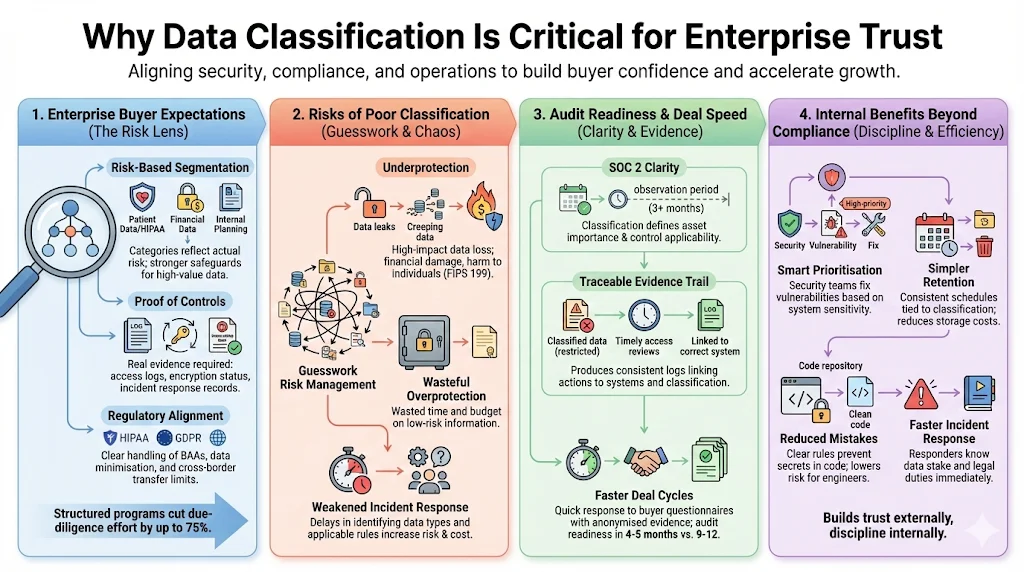
Enterprise buyer expectations around data protection
Enterprise buyers – especially in finance, healthcare, and critical infrastructure – use security due diligence to protect themselves from reputational harm and regulatory penalties. They expect:
-
Risk‑based segmentation. Data categories must map to risk. For example, PHI under HIPAA requires additional safeguards; intellectual property may necessitate different retention schedules. Using one label for all sensitive data signals immaturity.
-
Clear evidence of control operation. Buyers may request audit logs, access review records, cryptographic secret rotations, vulnerability management metrics, or proof of incident response testing.
-
Alignment with regulatory frameworks. In healthcare, BAAs are mandatory. For European clients, GDPR imposes data minimisation and cross‑border transfer restrictions. Classification ties these obligations to specific assets.
When classification is missing or poorly implemented, procurement teams prolong due diligence. They ask follow‑up questions, demand changes to contractual clauses, or reject the vendor. We have seen deals delayed by 3–6 months because the seller could not demonstrate consistent classification. On the other hand, when we implement classification programmes for clients, we reduce time spent on questionnaires by up to 75%. Buyers appreciate seeing how controls map to data types, which reduces friction and speeds up contract approvals.
How poor classification increases information risk management issues
Without classification, risk assessments become guesswork. Organisations may underprotect sensitive data or overspend on low‑risk data. FIPS 199 demonstrates that inappropriate protection can have severe consequences: a high‑impact breach could cause major financial loss or severe harm to individuals. Unclassified logs might contain API keys or credentials, turning a minor logging platform compromise into a catastrophic system breach. Likewise, misclassified development snapshots may contain real customer data, violating privacy regulations and contractual promises.
Role of classification in audit readiness and deal velocity
SOC 2 Type II audits require evidence across at least a three‑month observation period. Classification ensures that you collect the right evidence for the right assets. For example, access reviews for restricted data must happen monthly; cryptographic secret rotation must follow a defined cadence. When classification is clear, you can produce logs showing that these reviews occurred, and auditors can trace them back to relevant assets. Buyers often ask for anonymised evidence of access reviews or encryption results. Having a classification system means you can respond quickly without exposing sensitive information. Konfirmity’s managed service reduces time to readiness to 4–5 months on average – compared with 9–12 months for organisations that self‑manage.
Internal benefits aside from compliance
Apart from satisfying auditors and buyers, classification supports better internal decision‑making. Teams can prioritise vulnerability remediation based on the sensitivity of affected systems, assign budgets more effectively, and streamline retention schedules. Incident response becomes more efficient because responders know which data types are at stake and what legal or contractual obligations apply. Engineers appreciate clear guidance on where sensitive data is allowed, reducing the risk of accidentally storing secrets in code repositories.
Core Data Types Covered Under SOC 2
The scope of classification varies by business model, but most organisations should consider at least three broad categories:
1) Customer and user data
-
Personal data: Names, email addresses, contact information, IP addresses, and other personal identifiers. Under privacy regulations, this data requires protection and must be used only for authorised purposes. For healthcare organisations, PHI must follow HIPAA safeguards such as minimum necessary disclosure.
-
Sensitive personal data: Payment card details, national identification numbers, financial account information, or health data. Exposure can lead to identity theft or regulatory sanctions.
-
Enterprise customer records: Contracts, statements of work, support tickets, and logs containing proprietary information. These records may be subject to DPAs or confidentiality clauses.
2) Internal business data
-
Financial data: Revenue figures, budgets, payroll, investor reports. These typically require confidentiality to prevent insider trading or competitive disadvantage.
-
Product and source code: Intellectual property such as algorithms, architectural diagrams, or custom firmware. Access must be restricted and monitored; unauthorized disclosure can erode competitive advantage.
-
Strategic and operational data: Roadmaps, marketing strategies, board minutes, internal performance metrics. Exposure could damage market positioning or violate fiduciary duties.
3) System and security data
-
Logs and monitoring data: Application logs, infrastructure logs, SIEM data, and monitoring metrics. Logs may contain sensitive details like API secrets or user IDs; they must be classified and protected accordingly.
-
Access records: Authentication events, permission changes, and audit trails. These are crucial for evidence and must be retained according to classification.
-
Incident response artifacts: Root‑cause analyses, post‑mortem reports, and evidence collected during investigations. Often these documents contain sensitive technical details and must be restricted to authorised personnel.
Data classification protects your most sensitive assets before auditors even ask.
Share your work email and apply sensitivity tiers that hold up under enterprise scrutiny.
Defining Data Sensitivity and Confidentiality Levels
Common classification tiers
Based on industry practice and frameworks such as ISO 27001 and NIST, we recommend the four‑level tiering scheme introduced earlier. For quick reference:
Tier
Description
Examples
Controls
Public
Information intended for public disclosure; minimal risk if leaked
Marketing brochures, published documentation
No restriction; optional watermarking to discourage misuse
Internal
Business information meant for employees or contractors; limited impact if disclosed
Internal policies, organisational charts
Access control; basic authentication
Confidential
Sensitive business or customer data; moderate impact if disclosed
Financial forecasts, customer lists, proprietary analytics models
Encryption at rest and in transit, need-to-know access, retention rules
Restricted
Highly sensitive data with high impact if disclosed or tampered
Credentials, PHI, encryption secrets, trade secrets
MFA, strict RBAC, encryption, continuous monitoring, segmentation, DLP
Mapping sensitivity to business impact
Classification must connect to risk. FIPS 199 defines impact levels for confidentiality, integrity, and availability. We interpret those levels as follows:
-
Financial risk: For financial data, moderate or high classification translates to serious or severe financial loss if compromised. For example, leaked financial forecasts could affect investor relations and stock price.
-
Legal and regulatory exposure: PHI disclosure violates HIPAA and can lead to fines, breach notification obligations, and potential class‑action lawsuits. GDPR introduces significant fines for violations of data protection principles.
-
Customer trust and contractual risk: Breaches undermine trust and may trigger contract termination or damages. Many enterprise contracts include confidentiality clauses tied to classification levels. A breach of restricted data may breach confidentiality obligations and harm long‑term customer relationships.
Mapping Data Classification to the Data Lifecycle
Classification is not a one‑off exercise; it should influence controls throughout the data lifecycle.
1) Data creation and collection
-
Identifying classification at intake: At the point of collection, data owners or systems should determine the appropriate tier. For example, a sign‑up form requesting an email address and password generates restricted credentials and personal data. Tools can automatically tag records based on fields and context.
-
Assigning ownership: Every data set must have an owner responsible for classification, updates, and adherence to retention rules. ISO 27001 emphasises that asset owners evaluate potential impact and assign classifications.
2) Data storage and processing
-
Secure storage expectations by classification: Public and internal data may reside in standard storage with basic access control. Confidential data demands encryption at rest and in transit; restricted data should be stored in isolated environments with hardware security modules (HSMs) for secret management.
-
Segmentation and isolation: By segregating sensitive workloads into dedicated environments (e.g., separate VPCs, Kubernetes namespaces), you prevent cross‑contamination. Micro‑segmentation ensures that compromised systems cannot easily access restricted data.
3) Data access and use
-
Access control tied to sensitivity: Implement RBAC and attribute‑based access control (ABAC) policies that reflect classification. Internal data may require only single-factor authentication; restricted data must require MFA and just‑in‑time access approvals.
-
Least‑privilege principles: Users receive only the permissions needed for their job functions. Access reviews and certifications verify that permissions remain appropriate over time. SOC 2 auditors commonly inspect these reviews.
4) Data retention and deletion
-
Retention rules by data type: Classification informs how long data is stored. For example, logs containing restricted data may be retained for 90 days to support incident investigations, whereas internal data may be retained for a year to support operational analytics.
-
Secure disposal requirements: When data reaches the end of its lifecycle, disposal must follow classification: public data can be deleted without special measures; confidential and restricted data require secure wiping or cryptographic erasure to ensure irrecoverability.
Aligning Data Classification With SOC 2 Controls
The AICPA Trust Services Criteria require that controls align with risks, including those identified through classification. Below we map classification to specific control areas.
1) Logical access controls
-
Role‑based access: Define roles based on job responsibilities and tie them to classification tiers. For restricted data, implement just‑in‑time access, approvals, and periodic review. For internal data, standard RBAC may suffice.
-
Review and approval workflows: Access requests for sensitive data should pass through an approval workflow. Auditors expect to see evidence that such workflows are enforced and reviewed regularly.
2) Data protection measures
-
Encryption expectations: Confidential and restricted data must be encrypted at rest and in transit. According to IBM’s 2025 breach report, data discovery, classification, and encryption are fundamental to securing machine‑learning data and minimising breach costs.
-
Secret management practices: Cryptographic secrets should be stored in dedicated management services or HSMs. Separation of duties is critical; the same person should not manage those secrets and have access to the data they protect.
3) Monitoring and threat mitigation
-
Logging tied to sensitive data: Logging should capture access to restricted and confidential data. Tools like security information and event management (SIEM) must tag logs with classification metadata. Alerts should fire when sensitive data is accessed outside approved patterns.
-
Alerting on misuse or exposure: Use data loss prevention (DLP) tools to detect sensitive data leaving the environment. For restricted data, DLP rules should be more stringent and involve immediate incident response.
4) Incident response
-
Faster response through clear classification: When incidents occur, classification helps teams prioritise and scope investigations. A suspected leak of public data may not require urgent action; however, exposure of restricted credentials demands immediate containment and notification.
-
Scoping incidents based on data impact: Classification defines who must be notified (legal, compliance, customers), what remediation steps are required, and which regulators must be informed.
Building Data Classification Into Security Policies
Policies turn classification from theory into day‑to‑day practice. They must be usable and integrated into workflows rather than sitting on a shelf.
-
Writing clear classification rules: Each tier needs a concise description, examples of data types, and associated controls. Policies should reference regulatory obligations (e.g., HIPAA, GDPR) and contractual requirements. Avoid ambiguous terms like “secure” without defining expected controls.
-
Linking policies to daily workflows: Embed classification into development pipelines, ticket systems, and documentation. For instance, require that new features include a data flow diagram with classification tags. Automate tagging in code repositories, data stores, and backup systems.
-
Making policies usable, not shelfware: Use checklists and templates to guide teams. Provide a self‑service portal for classification questions. Feedback loops help refine policies based on actual usage.
-
Training teams without slowing delivery: Educate engineers, product managers, and support teams on classification using short, role‑based training modules. Provide concrete examples and tools. Reinforce training with periodic phishing and data‑handling tests.
Supporting Regulatory Requirements and Privacy Obligations
Regulatory frameworks like HIPAA, GDPR, and ISO 27001 place explicit obligations on data handling. Classification can simplify compliance by mapping regulations to specific assets and controls.
-
How classification helps meet privacy laws: HIPAA’s minimum necessary standard mandates limiting PHI disclosure to the least amount needed. Classification helps identify PHI and ensures that access rules enforce minimum necessary use. GDPR’s purpose limitation principle requires that personal data be processed only for stated purposes; classification ensures that consent and purpose are tracked per data type.
-
Handling customer‑specific contractual rules: Enterprise contracts may impose bespoke obligations for encryption, retention, or breach notification. Classification maps these clauses to specific data categories and systems. For example, a BAA may require 60‑day incident notification for PHI, while a DPA may require 30‑day deletion after contract termination.
-
Reducing audit friction across compliance standards: A well‑designed classification system supports cross‑framework compliance. For example, logs containing restricted data can satisfy both SOC 2 and ISO 27001 evidence requirements. Similarly, classification helps align HIPAA’s technical safeguards with SOC 2 confidentiality criteria and GDPR’s records of processing.
Operationalising Data Classification at Scale
1) Tooling and automation
Managing classification manually does not scale. Tools can automatically tag data based on schema, content, or context. Examples include data discovery platforms that scan databases and file systems, cloud providers’ tagging features, and infrastructure‑as‑code scripts that apply labels to resources. Automation reduces human error and ensures consistent application across environments. However, human oversight remains crucial, especially for context‑dependent data such as trade secrets or strategic plans.
2) Reducing manual effort
Automation should be paired with integration into existing workflows. For instance, configure your continuous integration (CI) pipeline to flag code that reads restricted data without using approved secrets management. Use policy‑as‑code to enforce classification at the infrastructure level. Automated scanning can highlight misclassified or unclassified data in SaaS tools like GitHub, Slack, or Jira.
3) Ownership and accountability
Roles must be clear. Data owners are responsible for classification and retention; system owners ensure that controls are implemented. Assign a classification steward or committee to oversee the programme, maintain policy, and handle exceptions. Establish a review cadence – quarterly or bi‑annually – to reassess classifications and update controls.
Common mistakes to avoid
-
Over‑classifying everything: Overly restrictive labels hinder collaboration and lead to costly encryption and access control overhead. Focus on business impact instead of paranoia.
-
Ignoring legacy systems: Older applications often house the most sensitive data. Auditors view classification as incomplete when these systems are excluded.
-
Treating classification as a one‑time task: Data evolves, businesses pivot, and regulations change. Regular reviews are essential. Build classification into change‑management and product design processes to maintain accuracy.
Preparing for SOC 2 Audits With Strong Classification
Evidence auditors ask for
Auditors expect to see that classification is documented, implemented, and actively maintained. Evidence may include:
-
Policies and procedures: Written classification policy with tiers, examples, controls, and roles. Documentation of review cadence and approval process.
-
Asset inventory: A complete list of assets with assigned classification levels, owners, and storage locations. Tools should generate this inventory automatically where possible.
-
Access reviews: Records showing periodic review of user and system access to restricted and confidential data. Evidence may include tickets, approvals, and remediation actions.
-
Encryption configurations: Proof that sensitive data is encrypted at rest and in transit. Provide configuration screenshots, cryptographic secret rotation logs, and statements from your cloud provider or HSM.
-
Monitoring and incident response: SIEM alerts tied to classified data, DLP reports, and incident response playbooks that reference classification. Post‑incident reports should detail how classification guided scoping and communications.
How to show classification in action
Auditors and buyers want assurance that classification is not just paperwork. Demonstrate:
-
Change‑management traces: Link tickets to classification updates when new data types are added or when classifications change. Show that owners review these changes.
-
Real examples: Provide sanitized audit logs where an attempt to access restricted data triggered an alert and subsequent investigation. Include evidence of corrective actions.
-
Continuous monitoring: Show dashboards or metrics illustrating classification coverage (e.g., percentage of databases with labels, number of unclassified files detected per month) and improvement over time.
Linking controls, policies, and real usage
Create a traceability matrix linking classification tiers to specific controls and evidence. For example, list which encryption keys protect restricted databases, which RBAC roles can read internal documents, and which SIEM rules monitor confidential logs. This mapping simplifies audit conversations and demonstrates maturity.
What enterprise customers often request post‑audit
After the SOC 2 report is issued, enterprise customers may still conduct due diligence. They often ask for:
Overview of findings and remediation: Explain any minor findings in the SOC 2 report and how classification contributed to or mitigated them.
-
Continued evidence of controls: Provide ongoing evidence such as quarterly access reviews, cryptographic secret rotations, or updated classification inventories. This demonstrates continuous compliance rather than a one‑off effort.
-
Mapping to their requirements: Buyers may provide their own security addenda. Use your classification system to map each requirement to relevant controls. For instance, if a buyer requires separate logging for PHI, show how restricted data classification triggers dedicated log segregation.
Conclusion
Treating data classification as a sales enabler rather than a compliance checkbox transforms how enterprise buyers perceive your organisation. A robust SOC 2 Data Classification Guide equips you with evidence, shortens due‑diligence cycles, and allows your team to focus on building. By identifying your most sensitive assets, assigning owners, enforcing controls, and continuously monitoring, you not only meet the AICPA criteria but also reduce the likelihood and impact of a breach. In a world where the average cost of a breach in the United States is over USD 10 million, investing in classification is both prudent and strategic. As we’ve seen through thousands of engagements, security that reads well in documents but fails under incident pressure is a liability. Build your programme once, operate it daily, and let compliance and trust follow.
FAQs
1. What level of detail do SOC 2 auditors expect for data classification?
Auditors expect to see a documented classification policy with clear definitions, examples, and controls. They also want to see an inventory of all assets with assigned classifications, evidence of regular reviews, and proof that controls (access, encryption, logging) align with each tier. Sanity‑checked sample data flows and tickets demonstrating classification decisions strengthen your case.
2. Does SOC 2 require a specific classification model?
No. The AICPA does not prescribe a particular model. However, your model must be risk‑based and documented. Many organisations adopt three‑ or four‑tier schemes (public, internal, confidential, restricted) or align with FIPS 199’s low/moderate/high impact categories. Choose a model that matches your business and regulatory landscape and ensure it is applied consistently.
3. How often should data classification be reviewed?
At minimum, annually. However, we recommend quarterly or after major changes (e.g., new products, acquisitions, regulatory updates). ISO 27001 explicitly calls for periodic review of classification schemes to ensure they reflect current business risks and regulatory requirements.
4. How does data classification affect access control decisions?
Classification informs the level of authentication, authorisation, and auditing required. For restricted data, implement MFA, just‑in‑time access, segregation of duties, and regular access reviews. For internal data, basic RBAC may suffice. Automate policy enforcement using attribute‑based access control to reduce manual errors.
5. Can automation replace manual classification efforts?
Automation can discover and label many data assets but cannot fully replace human judgement. Tools may misclassify context‑dependent data or fail to detect proprietary algorithms disguised as code comments. Use automation to scale discovery and monitoring, but retain human oversight for classification decisions, policy approval, and exceptions.
6. How does data classification support privacy controls and regulatory requirements?
Classification helps identify personal and sensitive data subject to HIPAA, GDPR, or other privacy laws. It ensures that minimum necessary use, purpose limitation, and consent requirements are enforced. During audits, classification demonstrates that you have mapped regulatory obligations to specific assets and controls, reducing friction and increasing confidence.



